
Voici la vérité dérangeante que la plupart des tableaux de bord de “ visibilité IA ” ne vous diront pas : l’outil d’analyse auquel vous faites confiance ne peut pas détecter les robots d’exploration que vous essayez de mesurer. GA4 fonctionne grâce à JavaScript, et les robots d’exploration IA ne l’exécutent presque jamais, donc L'analyse des fichiers journaux des robots d'indexation basés sur l'IA constitue la seule trace fiable permettant de savoir qui a récupéré quoi, à quel moment, et même s'il s'agissait bien d'utilisateurs réels.
Voici la procédure d'audit que j'applique lorsqu'un client souhaite savoir ce que les moteurs de recherche font réellement sur son site, comment distinguer un véritable robot d'un faux, et pourquoi bon nombre des craintes du type “ notre contenu sert à entraîner les moteurs de recherche ” s'avèrent infondées ou exagérées.
Principaux enseignements
- GA4 et la plupart des outils d'analyse ne peuvent pas détecter les robots d'indexation basés sur l'IA, car ceux-ci n'exécutent pas le code JavaScript qui déclenche la balise ; le journal d'accès au serveur est la seule source d'informations complète.
- Les robots d'apprentissage (GPTBot, ClaudeBot, CCBot) et les agents de recherche en temps réel (ChatGPT-User, OAI-SearchBot, PerplexityBot) remplissent des fonctions différentes ; bloquer un agent de recherche en temps réel vous empêche d'accéder aux réponses en temps réel, tandis que bloquer un robot d'apprentissage n'affecte que les futurs modèles.
- Une chaîne d'agent utilisateur peut être falsifiée en une seule ligne ; par conséquent, une grande partie des visites attribuées à des “ bots IA ” sont en réalité des visites usurpées. Vérifiez-les à l'aide des plages d'adresses IP publiées ou d'un DNS inversé confirmé en amont avant de prendre ces chiffres en compte.
- Le volume des robots d'indexation basés sur l'IA a connu une forte hausse (GPTBot a augmenté d'environ 305% et ChatGPT-User d'environ 2 825% en un an, selon Cloudflare) ; il s'agit donc désormais d'un véritable problème de charge et de budget d'indexation, et non plus d'un simple détail.
- La méthode qui permet réellement de prendre des décisions repose sur un recoupement à trois niveaux : les journaux du serveur par rapport à votre exploration ou à votre plan du site, d'une part, et les données d'analyse, d'autre part, le tout basé sur l'URL, les divergences fournissant alors des informations précieuses.
- Comparez les fichiers journaux avec le nombre d'octets que vous servez réellement : les robots d'indexation basés sur l'IA ignorent le JavaScript et cessent la lecture une fois la limite d'octets atteinte ; ainsi, un code d'état 200 ne signifie pas nécessairement que votre contenu a bien été indexé.
Pourquoi le GA4 et la plupart des analyses sont structurellement aveugles aux robots d'intelligence artificielle ?
GA4 est un outil de mesure côté client. Il charge une balise, celle-ci s'exécute dans un environnement similaire à celui d'un navigateur, puis un événement est envoyé. Sans exécution de JavaScript, il n'y a pas d'événement.
Les robots d'indexation basés sur l'IA se comportent comme des clients HTTP classiques : ils envoient une requête GET, analysent le code source côté serveur et ne modifient jamais vos balises. Ainsi, vos analyses comportementales n'afficheront aucune session provenant de GPTBot, même si vos journaux indiquent des dizaines de milliers de requêtes de sa part. Les gens en concluent alors que l’IA ne procède pas à l’exploration de leur site, alors que c’est le cas ; ils mesurent simplement avec un outil inadapté.
C'est la même raison architecturale pour laquelle votre contenu critique doit se trouver dans le code HTML brut, et non dans une coquille rendue par le client. Si un passage n'apparaît qu'après l'hydratation du JavaScript, un robot d'indexation qui n'exécute pas le JavaScript ne l'ingérera jamais. Les journaux rendent cela visible d'une manière qu'aucun test de rendu ne permet : vous voyez exactement quelles URL le robot a frappées et, en recoupant la réponse que votre serveur a renvoyée, exactement quels octets il a reçus.
Formation des robots d'indexation et des agents de recherche en direct : cesser de les traiter comme une seule et même chose
La plus grande erreur d'analyse que je constate consiste à regrouper tous les agents utilisateurs d'IA dans une seule catégorie, celle des “ bots IA ”. Ils remplissent des fonctions totalement différentes et exigent de vous des décisions différentes ; il est donc utile de les classer en deux grandes catégories.
Formation des robots d'indexation récolter du contenu pour construire ou affiner des modèles de base. Ils sont nombreux, systématiques et indifférents à l'attente d'un humain. Ce groupe comprend GPTBot (OpenAI), ClaudeBot (Anthropique), CCBot (Common Crawl, que de nombreux modèles ingèrent en aval), et l'accès contrôlé par Google-Extended (Le jeton de Google pour l'entraînement de Gemini, qui est une directive robots.txt plutôt qu'un user-agent d'exploration distinct). Le blocage de ces éléments a une incidence sur l'intégration de votre contenu dans le prochain modèle, mais n'a aucune incidence sur votre apparition dans une réponse en direct aujourd'hui.
Agents de recherche en direct récupérer une page parce qu'un utilisateur vient de poser une question et que le moteur a besoin d'une citation à l'instant même. C'est ce groupe qui est à l'origine de la visibilité de l'IA en matière de référencement : ChatGPT-User (recherche à la demande d'OpenAI lorsqu'un utilisateur demande à ChatGPT de naviguer), OAI-SearchBot (l'index d'OpenAI pour les résultats de recherche de ChatGPT), et PerplexityBot (Récupération de la perplexité). Si vous bloquez ces éléments, vous vous excluez de la réponse.
C’est là que le regroupement fait vraiment mal. De nombreux sites bloquent systématiquement “ AI ” dans leur fichier robots.txt, ce qui empêche l’accès à OAI-SearchBot et ChatGPT-User ainsi qu’à GPTBot, puis ils se demandent pourquoi ils ont disparu des citations de ChatGPT. En bloquant les agents de récupération en même temps que le robot d’indexation d’entraînement, ils coupent l’accès aux robots mêmes qui les mettaient en avant auprès des utilisateurs.
Présentation par OpenAI de ses propres robots d'indexation Cela illustre cette distinction et le contrôle indépendant qu’elle vous confère : vous pouvez autoriser OAI-SearchBot à apparaître dans les résultats de recherche tout en empêchant GPTBot de se désengager de l’apprentissage. Si vous traitez ces deux catégories comme une seule et même entité, toutes les décisions que vous prendrez par la suite seront erronées.
Une antisèche sur les user-agents
| Jeton d'agent utilisateur | Opérateur | Classe | Ce que le blocage vous coûte |
|---|---|---|---|
| GPTBot | OpenAI | Formation | Données d'entraînement du futur modèle uniquement |
| OAI-SearchBot | OpenAI | Récupération / index | Out of ChatGPT search results |
| ChatGPT-User | OpenAI | Récupération en direct | Ne peut être récupéré lorsqu'un utilisateur demande à ChatGPT de naviguer |
| ClaudeBot | Anthropique | Formation | Hors futures données de formation de Claude |
| PerplexityBot | Perplexité | Récupération / index | Réponses et citations sur la perplexité |
| CCBot | Rampe commune | Formation (en amont) | A partir d'un ensemble de données que de nombreux modèles ingèrent |
| Google-Extended | Contrôle de la formation (jeton robot) | Hors formation Gémeaux ; n'affecte pas la recherche |
La croissance qui rend cette mesure non optionnelle
Il s'agissait d'une note de bas de page il y a deux ans, et c'est désormais une ligne budgétaire. Analyse à l'échelle du réseau de Cloudflare a révélé qu'entre mai 2024 et mai 2025, le nombre de requêtes adressées à GPTBot a augmenté d'environ 305% tandis que le nombre total de requêtes Googlebot a augmenté d'environ 96%. Le chiffre le plus frappant est celui de la recherche en direct : ChatGPT-Les demandes des utilisateurs ont augmenté d'environ 2 825% au cours de la même période, ce qui reflète la fréquence à laquelle les utilisateurs demandent désormais à ChatGPT d'aller chercher une page en direct.
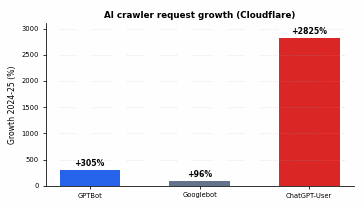
Une multiplication par près de 30 du trafic généré par un seul agent de récupération n’est pas un bruit de fond que l’on peut ignorer sur un hébergement mutualisé. Il s’agit bien de bande passante réelle, d’une charge réelle sur le serveur d’origine et d’une concurrence réelle sur le budget d’exploration. Ce qui nous amène à la deuxième réalité difficile à accepter : une grande partie du trafic prétendant provenir de ces robots n’est pas ce qu’elle prétend être.
Vérification des DNS inversés : la plupart du trafic des “robots d'intelligence artificielle” figurant dans vos journaux est usurpé.
Une chaîne « user-agent » n'est qu'un en-tête de requête, et n'importe qui peut la définir. La définition User-Agent : GPTBot Il s'agit d'une modification d'une seule ligne, et les robots d'indexation, les contournements de paywall et les concurrents le font constamment, car le modèle « allow-by-user-agent » se fie naïvement à cette affirmation. Si vous établissez un rapport d'exploration en vous basant uniquement sur le champ « user-agent », vous rapportez des informations erronées ; la vérification constitue donc la première étape de filtrage avant que les chiffres que vous produisez n'aient la moindre valeur.
Il existe deux méthodes fiables, par ordre de préférence.
1. Fichiers de plages IP publiés. Les opérateurs sérieux publient des listes d'adresses IP lisibles à la machine, que vous pouvez comparer. OpenAI publie gptbot.json, searchbot.json et chatgpt-user.json; Common Crawl publie ses plages d'adresses ; Google publie ses listes d'adresses IP de robots d'indexation. Il suffit de comparer l'adresse IP d'origine de la requête avec le fichier correspondant ; si elle ne figure pas dans la liste, cela signifie que l'agent utilisateur est falsifié. Il s'agit de la méthode de vérification la plus fiable, car elle ne repose absolument pas sur le DNS.
2. Reverse-DNS plus forward-confirm. Pour les fournisseurs qui ne publient pas de fichiers IP (ClaudeBot d’Anthropic en est un exemple notable), utilisez la même technique de DNS inversé confirmé en amont. Google recommande de vérifier Googlebot depuis des années.
La logique : faire une recherche inverse sur l'IP source pour obtenir un nom d'hôte, confirmer que le nom d'hôte appartient à l'opérateur revendiqué, puis faire une recherche directe sur ce nom d'hôte et confirmer qu'il se résout vers l'IP d'origine. Les deux directions doivent être concordantes.
# Etape 1 : recherche inversée de l'IP qui prétend être un bot
dig -x 66.249.66.1 +court
# -> crawl-66-249-66-1.googlebot.com.
# Etape 2 : recherche de ce nom d'hôte
dig crawl-66-249-66-1.googlebot.com +short
# -> 66.249.66.1 (correspond : vérifié)
# Si le nom d'hôte n'appartient pas à l'opérateur,
# ou si le forward lookup ne renvoie pas l'IP d'origine,
# la requête est usurpée. L'écarter avant de la signaler.Testez cela sur un échantillon de tous les user-agents qui vous intéressent. Sur la plupart des sites que j’audite, une part non négligeable des requêtes provenant de “ GPTBot ” et “ PerplexityBot ” échoue à la vérification. D’après mon expérience, le fait de présenter des agents utilisateurs non vérifiés comme de véritables activités de crawl par IA est l’une des façons les plus courantes pour un audit de finir par induire en erreur le client qui l’a commandé.
La référence croisée : logs vs crawl vs analytics
Une seule source de données ment par omission. La méthode qui produit réellement des décisions est une réconciliation à trois voies. Chaque source répond à une question différente, et c'est dans les intervalles entre elles que réside l'intelligence.
- Journaux du serveur Réponse : qu'ont réellement demandé les bots et les utilisateurs, et quel code d'état avons-nous renvoyé ? C'est la référence absolue en matière de comportement.
- Le propre crawler d'un crawler (Screaming Frog, Sitebulb, ou l'exportation de votre sitemap) répond : quelles URL existent et devraient être accessibles ?
- Analytique et Search Console réponse : avec quoi les humains se sont-ils engagés et qu'est-ce qui a créé de la valeur ?
Mettez les trois côte à côte, avec l'URL comme clé, et lisez les différences :
| Dans les journaux ? | Dans le crawl/sitemap ? | En matière d'analyse ? | Ce que cela signifie |
|---|---|---|---|
| Oui (AI bot) | Oui | Pas de trafic humain | L'IA l'ingère mais les humains n'atterrissent pas. Candidat à une valeur réservée à l'IA, ou à un contenu superficiel sur lequel le robot gaspille son budget. |
| Oui (robot IA, lourd) | Non | Non | Le robot martèle les URL que vous ne répertoriez même pas : explosions de paramètres, filtres à facettes, vieilles saletés paginées. Gaspillage du budget de crawl. |
| Non | Oui | Oui | Page importante qu'aucun robot d'indexation n'est allé chercher. Vérifiez le fichier robots.txt, les liens internes et la présence de HTML brut. |
| Oui (retours 404/5xx) | Oui | s/o | Vous fournissez des erreurs aux robots d'indexation de l'IA. Ils apprennent que votre site est défectueux ; les agents de recherche vous excluent des réponses. |
Une méthodologie concrète et reproductible : exportez votre journal d'accès pour une fenêtre de 30 jours, filtrez uniquement les hits de robots vérifiés, normalisez l'URL (supprimez les paramètres de session que vous ne souhaitez pas voir pris en compte), puis joignez à gauche votre sitemap et votre exportation de la Search Console sur la clé d'URL. Regroupez les données par classe d'agent utilisateur (formation ou récupération) et par code d'état.
En un après-midi, vous saurez quelles URL les moteurs de réponse recherchent réellement, lesquelles ils gaspillent les requêtes, et lesquelles de vos pages d'argent ils n'ont jamais touchées. On est loin de l'idée selon laquelle “l'IA nous fouille beaucoup”.”
Repérer les gaspillages de budget avant qu'ils ne vous coûtent cher
Le budget de crawl était une conversation entre Google et les robots. Il s'agit désormais d'une conversation entre robots d'IA, et les robots d'IA sont beaucoup moins disciplinés. Les signatures de déchets pour chasser dans les journaux des robots vérifiés :
- Explosion des paramètres et des facettes. Comptez les URL distinctes par modèle. Si un robot a récupéré 12 000 variantes de
/shop/?color=&size=&sort=, c'est-à-dire un budget consacré à des produits presque identiques plutôt qu'à vos pages de catégories et de produits. - Répartition des codes d'état par bot. Un profil sain se compose essentiellement de chaînes 200. Une part croissante de chaînes 301/302 signifie que le robot brûle les requêtes sur les redirections ; une part croissante de 404/410 signifie qu'il chasse les URL mortes ; 5xx signifie que votre origine plie sous la charge.
- Recherche répétée d'URL inchangés. Si un agent de récupération réactualise la même page toutes les heures avec un code 200 et que vous ne la modifiez pas, vos en-têtes de mise en cache et de requête conditionnelle (ETag, Last-Modified) ne sont ni pris en compte ni envoyés.
- Les robots accèdent à des URL interdites dans le fichier robots.txt. Les robots qui se comportent bien le respectent ; les connexions à des chemins interdits à partir d'une adresse IP vérifiée méritent un examen plus approfondi, et les connexions à partir d'adresses IP non vérifiées confirment le problème d'usurpation d'identité évoqué plus haut.
Cela est d'autant plus important dans le cas d'un hébergement partagé ou modeste. Un bond de 30 fois dans un agent de récupération, multiplié par tous les autres, est un profil de charge pour lequel votre pile n'a pas été prévue. Si vous constatez une tension sur l'origine du trafic des robots, la solution est en partie architecturale et ne se limite pas à des modifications du fichier robots.txt : la mise en cache, les requêtes conditionnelles et le fait de savoir si l'agent de recherche est en mesure d'accéder à l'ensemble du site. votre installation WordPress peut effectivement gérer le volume de la demande avant d'en inviter d'autres.
Pourquoi les journaux et la règle des 2MB se renforcent-ils mutuellement ?
Deux facteurs entrent ici en ligne de compte. Premièrement, les robots d’indexation basés sur l’IA n’exécutent pas le JavaScript ; par conséquent, tout ce qui ne figure pas dans le code HTML brut leur est invisible. Deuxièmement, les robots d’indexation sont soumis à des limites en octets quant à la quantité de contenu d’un document qu’ils lisent réellement : Googlebot, par exemple, ne lit que les 2 premiers Mo d'une page, et un code de balisage trop volumineux repousse votre contenu réel au-delà de la limite.
Vos journaux afficheront un code de statut 200 indiquant que la requête s'est déroulée sans problème, ce qui semble correct, alors que le bot n'a en réalité récupéré que la première partie d'une page de 4 Mo. Le code de statut est trompeur, car il se montre trop généreux. C'est précisément pour cette raison que l'analyse des journaux doit s'accompagner d'une connaissance précise des octets que vous servez réellement : un code 200 est nécessaire, mais pas suffisant.
Alors, que faut-il faire concrètement ?
La plupart des rapports sur la visibilité de l'IA reposent sur les deux fondements les plus fragiles qui soient : un outil d'analyse incapable de détecter le trafic, et une chaîne d'agent utilisateur que n'importe qui peut falsifier. Le journal du serveur est le seul élément qui consigne ce qui s'est réellement passé, mais même celui-ci n'a aucune valeur tant que l'on n'a pas vérifié l'identité du demandeur et distingué l'entraînement de la consultation.
À mon sens, la démarche est simple, même si le travail n’a rien de prestigieux : effectuez un recoupement à trois niveaux et vérifiez chaque bot avant de le comptabiliser. En procédant ainsi, vous cesserez de deviner comment fonctionnent les robots d’indexation basés sur l’IA et commencerez à les gérer. Si vous ne le faites pas, vous prenez des décisions concernant le fichier robots.txt qui vous excluent discrètement des réponses que vos clients obtiennent déjà ailleurs.
Journal des mises à jour
22 juin 2026
- J'ai commencé par un bref résumé, puis j'ai ajouté une synthèse des points clés et une table des matières.
- Les sources provenant d'OpenAI, de Cloudflare et de Google Search Central ont été intégrées dans le texte sous forme de citations.
- J'ai reformulé le texte en adoptant un ton mesuré, propre à un consultant, et j'ai donné à la conclusion une tournure plus orientée vers l'expression d'une opinion.
Vous souhaitez que nos publications apparaissent plus souvent sur Google ?
En un clic, Google affichera ce site dans votre rubrique « À la une ».


