
Hier ist die unangenehme Wahrheit, die Ihnen die meisten Dashboards zur “KI-Transparenz” verschweigen: Das Analysetool, dem Sie vertrauen, kann die Crawler, die Sie messen möchten, nicht erkennen. GA4 wird über JavaScript ausgeführt, und KI-Crawler führen JavaScript so gut wie nie aus, daher Die Analyse von Protokolldateien für KI-Crawler ist die einzige verlässliche Aufzeichnung darüber, wer wann welche Daten abgerufen hat und ob es sich dabei überhaupt um echte Nutzer handelte.
Dies ist das Audit-Handbuch, das ich verwende, wenn ein Kunde wissen möchte, wie sich die Suchalgorithmen tatsächlich auf seine Website auswirken, wie man einen echten Bot von einem gefälschten unterscheiden kann und warum sich viele der Befürchtungen, dass “unsere Inhalte als Trainingsdaten verwendet werden”, als unbegründet oder übertrieben herausstellen.
Wichtigste Erkenntnisse
- GA4 und die meisten Analysetools können KI-Crawler nicht erfassen, da diese Crawler das JavaScript, das das Tag auslöst, nicht ausführen; das Server-Zugriffsprotokoll ist die einzige vollständige Aufzeichnung.
- Trainings-Crawler (GPTBot, ClaudeBot, CCBot) und Live-Abfrageagenten (ChatGPT-User, OAI-SearchBot, PerplexityBot) erfüllen unterschiedliche Aufgaben; wenn Sie einen Abfrageagenten blockieren, erhalten Sie keine Live-Antworten mehr, während das Blockieren eines Trainings-Crawlers sich nur auf zukünftige Modelle auswirkt.
- Eine User-Agent-Zeichenkette lässt sich in einer einzigen Zeile fälschen, sodass ein großer Teil der Zugriffe durch “KI-Bots” gefälscht ist; überprüfen Sie diese anhand veröffentlichter IP-Bereiche oder durch Forward- und Reverse-DNS-Abfragen, bevor Sie irgendetwas zählen.
- Das Volumen der KI-Crawler ist rasant gestiegen (GPTBot um etwa 305%, ChatGPT-Nutzer um etwa 2,825% innerhalb eines Jahres, laut Cloudflare), sodass dies mittlerweile ein echtes Problem hinsichtlich der Auslastung und des Crawling-Budgets darstellt und nicht mehr nur eine Randnotiz ist.
- Die Methode, die tatsächlich zu Entscheidungen führt, ist ein dreifacher Abgleich: Serverprotokolle mit Ihrem Crawl oder Ihrer Sitemap und den Analysedaten, wobei die URL als Schlüssel dient – die Erkenntnisse ergeben sich aus den Abweichungen.
- Vergleichen Sie die Logs mit der tatsächlich ausgelieferten Byte-Anzahl: KI-Crawler ignorieren JavaScript und brechen das Einlesen ab, sobald ein bestimmtes Byte-Limit überschritten wird. Ein reiner 200-Status bedeutet also nicht, dass Ihr Inhalt tatsächlich erfasst wurde.
Warum sind GA4 und die meisten Analyseprogramme strukturell blind für KI-Bots?
GA4 ist ein clientseitiges Messinstrument. Es lädt ein Tag, das Tag wird in einer browserähnlichen Umgebung ausgeführt, und es wird ein Ereignis gesendet. Ohne JavaScript-Ausführung gibt es kein Ereignis.
KI-Crawler verhalten sich wie klassische HTTP-Clients: Sie senden einen GET-Befehl, analysieren das Markup serverseitig und greifen niemals auf Ihr Tag zu. Daher werden in Ihrer Verhaltensanalyse keine Sitzungen von GPTBot angezeigt, obwohl Ihre Protokolle Zehntausende seiner Anfragen verzeichnen. Man kommt dann zu dem Schluss, dass die KI die Seite nicht crawlt, obwohl sie es tatsächlich tut; man misst einfach mit dem falschen Instrument.
Dies ist derselbe architektonische Grund, warum Ihre kritischen Inhalte im rohen HTML und nicht in einer vom Client gerenderten Shell vorliegen müssen. Wenn eine Passage erst nach der JavaScript-Hydrierung erscheint, wird ein KI-Crawler, der JS nicht ausführt, sie nie aufnehmen. Die Protokolle machen dies auf eine Art und Weise sichtbar, wie es kein Rendering-Test kann: Sie sehen genau, welche URLs der Bot aufgerufen hat, und durch Querverweise auf die von Ihrem Server zurückgegebene Antwort, welche Bytes er genau erhalten hat.
Schulungs-Crawler vs. Live-Retrieval-Agenten: Hören Sie auf, beide als eine Sache zu behandeln
Der größte analytische Fehler, den ich sehe, besteht darin, alle KI-User-Agents in einen Topf als “KI-Bots” zu werfen. Sie erfüllen völlig unterschiedliche Funktionen und erfordern von Ihnen unterschiedliche Entscheidungen; daher ist es hilfreich, von zwei großen Klassen auszugehen.
Ausbildung der Crawler Inhalte sammeln, um Grundmodelle zu erstellen oder zu verfeinern. Sie arbeiten massenhaft, systematisch und es ist ihnen gleichgültig, ob ein Mensch wartet. Zu dieser Gruppe gehören GPTBot (OpenAI), ClaudeBot (Anthropisch), CCBot (Common Crawl, das viele Modelle nachgelagert einlesen), und der Zugriff, der durch Google-Extended (Googles Token für das Gemini-Training, bei dem es sich um eine robots.txt-Anweisung und nicht um einen separaten Crawling-User-Agent handelt). Das Blockieren dieser Anweisungen hat Einfluss darauf, ob Ihre Inhalte in das nächste Modell einfließen, hat jedoch keinen Einfluss darauf, ob Sie heute in einer Live-Antwort erscheinen.
Live-Abrufagenten eine Seite abrufen, weil ein Nutzer gerade eine Frage gestellt hat und die Suchmaschine jetzt ein Zitat benötigt. Dies ist die Gruppe, die die Sichtbarkeit von KI-Empfehlungen tatsächlich vorantreibt: ChatGPT-Benutzer (OpenAIs On-Demand-Fetch, wenn ein Benutzer ChatGPT zum Durchsuchen auffordert), OAI-SearchBot (OpenAIs Index für ChatGPT-Suchergebnisse), und PerplexityBot (Perplexitys Rückgriff). Wenn du diese blockierst, schließt du dich selbst aus der Antwort aus.
Genau hier macht sich die pauschale Blockierung besonders schmerzlich bemerkbar. Viele Websites blockieren “AI” pauschal in der robots.txt-Datei, wodurch neben dem GPTBot auch der OAI-SearchBot und der ChatGPT-User aussortiert werden – und dann wundern sie sich, warum sie aus den ChatGPT-Zitaten verschwunden sind. Indem sie die Abruf-Agenten zusammen mit dem Trainings-Crawler blockieren, schneiden sie genau jene Bots ab, die sie den Nutzern eigentlich präsentierten.
OpenAI-eigener Überblick über seine Crawler Dies verdeutlicht diese Trennung und die damit verbundene unabhängige Kontrolle, die Sie dadurch erhalten: Sie können zulassen, dass der OAI-SearchBot in den Suchergebnissen erscheint, während Sie dem GPTBot die Teilnahme am Training verweigern. Wenn Sie die beiden Klassen als eine einzige behandeln, ist jede weitere Entscheidung, die Sie treffen, falsch.
Ein funktionierender Spickzettel für Benutzer-Agenten
| Benutzer-Agent-Token | Betreiber | Klasse | Was eine Sperrung Sie kostet |
|---|---|---|---|
| GPTBot | OpenAI | Ausbildung | Nur aus den Trainingsdaten des zukünftigen Modells |
| OAI-SearchBot | OpenAI | Abruf / Index | Außerhalb der ChatGPT-Suchergebnisse |
| ChatGPT-Benutzer | OpenAI | Live-Abruf | Kann nicht abgerufen werden, wenn ein Benutzer ChatGPT zum Durchsuchen auffordert |
| ClaudeBot | Anthropisch | Ausbildung | Aus den zukünftigen Claude-Trainingsdaten |
| PerplexityBot | Perplexität | Abruf / Index | Antworten und Zitate von Out of Perplexity |
| CCBot | Gemeinsames Kriechen | Ausbildung (vorgelagert) | Aus einem Datensatz nehmen viele Modelle auf |
| Google-Extended | Trainingssteuerung (Roboter Token) | Außerhalb des Gemini-Trainings; wirkt sich nicht auf die Suche aus |
Das Wachstum, das dies zu einer nicht-optionalen Option macht
Vor zwei Jahren war dies noch eine Fußnote, heute ist es ein Haushaltsposten. Die netzwerkweite Analyse von Cloudflare ergab, dass die GPTBot-Anfragen zwischen Mai 2024 und Mai 2025 um etwa 305% während die Googlebot-Anfragen insgesamt um 96% zunahmen. Die auffälligste Zahl ist die des Live-Abrufs: ChatGPT-Benutzeranfragen stiegen um 2.825% im gleichen Zeitraum, was zeigt, wie oft die Nutzer ChatGPT jetzt bitten, eine Live-Seite aufzurufen.
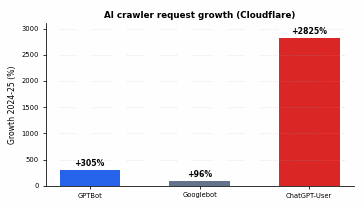
Eine fast 30-fache Zunahme bei einem Abrufagenten ist auf einem Shared-Host kein Rauschen, das man einfach ignorieren kann. Es handelt sich um echte Bandbreite, echte Auslastung des Ursprungsservers und echten Wettbewerb um das Crawl-Budget. Das bringt uns zur zweiten harten Wahrheit: Ein großer Teil des Datenverkehrs, der vorgibt, von diesen Bots zu stammen, ist nicht das, was er zu sein vorgibt.
Reverse-DNS-Verifizierung: Der meiste “AI-Bot”-Verkehr in Ihren Protokollen ist gefälscht
Ein User-Agent-String ist lediglich ein Request-Header, und jeder kann ihn festlegen. Das Festlegen Benutzer-Agent: GPTBot Das ist eine Änderung von nur einer Zeile, und Webcrawler, Paywall-Umgehungsprogramme und Wettbewerber machen das ständig, weil das gesamte „Allow-by-User-Agent“-Modell dieser Angabe naiv vertraut. Wenn Sie einen Crawling-Bericht direkt auf der Grundlage des User-Agent-Feldes erstellen, liefern Sie falsche Angaben; daher ist die Überprüfung der erste Filterschritt, bevor die von Ihnen ermittelten Zahlen überhaupt aussagekräftig sind.
Es gibt zwei zuverlässige Methoden, die in der Reihenfolge ihrer Anwendung bevorzugt werden.
1. Veröffentlichte IP-Bereichsdateien. Die seriösen Betreiber veröffentlichen maschinenlesbare IP-Listen, die Sie abgleichen können. OpenAI veröffentlicht gptbot.json, searchbot.json und chatgpt-user.json; Common Crawl veröffentlicht seine IP-Bereiche; Google veröffentlicht seine Crawler-IP-Listen. Vergleichen Sie die Quell-IP der Anfrage mit der entsprechenden Datei – ist sie nicht in der Liste enthalten, handelt es sich um einen gefälschten User-Agent. Dies ist die sauberste Überprüfungsmethode, da sie überhaupt nicht auf DNS angewiesen ist.
2. Reverse-DNS plus Vorwärts-Bestätigung. Bei Anbietern, die keine IP-Dateien veröffentlichen (ein bekanntes Beispiel hierfür ist der ClaudeBot von Anthropic), verwenden Sie dieselbe Technik der vorwärtsbestätigten Reverse-DNS. Google hat empfohlen, Googlebot zu verifizieren seit Jahren.
Die Logik: Führen Sie einen Reverse-Lookup für die Quell-IP durch, um einen Hostnamen zu erhalten, bestätigen Sie, dass der Hostname zum beanspruchten Betreiber gehört, führen Sie dann einen Forward-Lookup für diesen Hostnamen durch und bestätigen Sie, dass er zur ursprünglichen IP zurückführt. Beide Richtungen müssen übereinstimmen.
# Schritt 1: Reverse-Lookup der IP, die behauptet, ein Bot zu sein
dig -x 66.249.66.1 +kurz
# -> crawl-66-249-66-1.googlebot.com.
# Schritt 2: Vorwärtssuche nach diesem Hostnamen
dig crawl-66-249-66-1.googlebot.com +kurz
# -> 66.249.66.1 (Treffer: verifiziert)
# Wenn der Hostname nicht zum Betreiber gehört,
# oder der Forward Lookup liefert nicht die ursprüngliche IP,
# ist die Anfrage gefälscht. Verwerfen Sie sie vor der Meldung.Führen Sie dies mit einer Stichprobe aller User-Agents durch, die für Sie von Bedeutung sind. Auf den meisten Websites, die ich prüfe, fällt ein erheblicher Teil der Zugriffe von “GPTBot” und “PerplexityBot” bei der Verifizierung durch. Die Meldung nicht verifizierter User-Agents als echte KI-Crawling-Aktivitäten ist meiner Erfahrung nach eine der häufigsten Ursachen dafür, dass ein Audit den Kunden, der dafür bezahlt hat, in die Irre führt.
Der Querverweis: Logs vs Crawl vs Analytics
Eine einzige Datenquelle lügt durch Auslassung. Die Methode, die tatsächlich zu Entscheidungen führt, ist ein dreifacher Abgleich. Jede Quelle beantwortet eine andere Frage, und die Lücken dazwischen sind die Quelle der Erkenntnis.
- Server-Protokolle Antwort: Was haben Bots und Nutzer tatsächlich angefordert, und welchen Statuscode haben wir zurückgegeben? Das ist die „Ground Truth“ für das Verhalten.
- Das eigene Kriechen eines Kriechers (Screaming Frog, Sitebulb oder Ihr Sitemap-Export) antwortet: Welche URLs glauben wir, dass sie existieren und erreichbar sein sollten?
- Analytik und Suchkonsole Antwort: Womit haben sich die Menschen beschäftigt, und was hat den Wert bestimmt?
Legen Sie die drei nebeneinander, verschlüsselt auf URL, und lesen Sie die Unterschiede:
| In Protokollen? | In Crawl/Sitemap? | In der Analytik? | Was es bedeutet |
|---|---|---|---|
| Ja (KI-Bot) | Ja | Kein menschlicher Verkehr | Die KI nimmt sie auf, aber der Mensch landet nicht. Ein Kandidat für reine KI-Inhalte oder dünne Inhalte, für die der Bot Budget verschwendet. |
| Ja (KI-Bot, schwer) | Nein | Nein | Der Bot stürzt sich auf URLs, die Sie nicht einmal auflisten: Parameterexplosionen, Facettenfilter, alter paginierter Müll. Verschwendung von Crawl-Budget. |
| Nein | Ja | Ja | Wichtige Seite, die kein AI-Crawler abgerufen hat. Überprüfen Sie robots.txt, interne Links und dass die Seite in Roh-HTML vorliegt. |
| Ja (gibt 404/5xx zurück) | Ja | k.A. | Sie füttern die AI-Crawler mit Fehlern. Sie erfahren, dass Ihre Website fehlerhaft ist; Abrufagenten lassen Sie aus den Antworten fallen. |
Eine konkrete, wiederholbare Methode: Exportieren Sie Ihr Zugriffsprotokoll für ein sauberes 30-Tage-Fenster, filtern Sie nur verifizierte Bot-Treffer, normalisieren Sie die URL (entfernen Sie Sitzungsparameter, die nicht gezählt werden sollen), und verknüpfen Sie dann Ihre Sitemap und Ihren Search-Console-Export über den URL-Schlüssel. Gruppieren Sie nach User-Agent-Klassen (Training vs. Abruf) und nach Statuscode.
Innerhalb eines Nachmittags werden Sie wissen, welche URLs die Antwortmaschinen tatsächlich abrufen, welche sie mit Anfragen vergeuden und welche Ihrer Geldseiten sie noch nie angefasst haben. Das ist weit entfernt von “KI crawlt uns oft”.”
Erkennen von Verschwendung im Kriechbudget, bevor sie Sie kostet
Das Crawl-Budget war eine Googlebot-Konversation. Jetzt ist es auch eine KI-Bot-Konversation, und die KI-Crawler sind weit weniger diszipliniert. Die Abfallsignaturen sind in den Protokollen der verifizierten Bots zu finden:
- Parameter- und Facettenexplosionen. Zählen Sie unterschiedliche URLs pro Vorlage. Wenn ein Bot 12.000 Varianten von
/shop/?color=&size=&sort=, Das heißt, das Budget wird für Beinahe-Duplikate ausgegeben, anstatt für Ihre Kategorie- und Produktseiten. - Statuscode-Verteilung pro Bot. Ein gesundes Profil besteht zumeist aus 200ern. Ein steigender Anteil von 301/302-Ketten bedeutet, dass der Bot Anfragen auf Weiterleitungen verbrennt; ein steigender Anteil von 404/410 bedeutet, dass er toten URLs hinterherläuft; 5xx bedeutet, dass Ihr Ursprung unter der Last zusammenbricht.
- Wiederholte Abrufe von unveränderten URLs. Wenn ein Abruf-Agent dieselbe Seite stündlich erneut abruft und dabei den Status 200 zurückgibt, Sie diese Seite aber nicht ändern, werden Ihre Caching- und bedingten Anfrage-Header (ETag, Last-Modified) nicht berücksichtigt oder gesendet.
- Bot-Treffer auf URLs, die in robots.txt verboten sind. Wohlerzogene Bots respektieren sie; Treffer auf nicht zugelassene Pfade von einer verifizierten IP sind einen genaueren Blick wert, und Treffer von nicht verifizierten IPs bestätigen das oben beschriebene Spoofing-Problem.
Bei gemeinsam genutztem oder bescheidenem Hosting ist dies sogar noch wichtiger. Ein 30-facher Sprung bei einem Abrufagenten, multipliziert mit allen anderen, ist ein Lastprofil, für das Ihr Stack nicht vorgesehen war. Wenn Sie eine Belastung durch Bot-Verkehr feststellen, liegt die Lösung teilweise in der Architektur und nicht nur in der Bearbeitung von robots.txt: Caching, bedingte Anfragen und das Wissen, ob Ihr WordPress-System kann das Anfragevolumen tatsächlich bewältigen bevor Sie noch mehr davon einladen.
Warum die Protokolle und die 2-MB-Regel sich gegenseitig verstärken
Hier kommen zwei Faktoren zusammen. Erstens führen KI-Crawler kein JavaScript aus, sodass alles, was nicht im reinen HTML-Code enthalten ist, für sie unsichtbar bleibt. Zweitens gibt es für Crawler Byte-Beschränkungen hinsichtlich der Menge an Daten, die sie tatsächlich aus einem Dokument lesen: Googlebot beispielsweise, liest nur die ersten 2 MB einer Seite, und überflüssiger Markup-Code verschiebt Ihren eigentlichen Inhalt hinter die Schnittstelle.
In Ihren Logs wird der Abruf als einwandfreier 200er-Status angezeigt, was auf den ersten Blick in Ordnung erscheint, während der Bot still und leise nur den ersten Ausschnitt einer 4-MB-Seite abgerufen hat. Der Statuscode täuscht, da er zu großzügig ausfällt. Genau aus diesem Grund muss die Log-Analyse mit dem Wissen darüber einhergehen, welche Bytes tatsächlich ausgeliefert werden: Ein 200er-Status ist notwendig, aber nicht ausreichend.
Also, was solltest du eigentlich tun?
Die meisten Berichte zur KI-Transparenz basieren auf den beiden schwächsten möglichen Grundlagen: einem Analysetool, das den Datenverkehr nicht erfassen kann, und einer User-Agent-Zeichenkette, die jeder fälschen kann. Das Serverprotokoll ist das einzige Dokument, das aufzeichnet, was tatsächlich geschehen ist, und selbst dieses ist wertlos, solange man den Aufrufer nicht verifiziert und das Training vom Abruf trennt.
Meiner Meinung nach ist der Schritt ganz einfach, auch wenn die Arbeit nicht gerade glamourös ist: Führen Sie den dreifachen Abgleich durch und überprüfen Sie jeden Bot, bevor Sie ihn zählen. Wenn Sie das tun, hören Sie auf, über KI-Crawler zu spekulieren, und fangen an, sie zu verwalten. Wenn du das überspringst, triffst du Entscheidungen bezüglich der robots.txt, die dich still und leise aus den Suchergebnissen verdrängen, die deine Kunden bereits anderswo erhalten.
Änderungsprotokolle
22. Juni 2026
- Mit einer kurzen Zusammenfassung eingeleitet, eine Übersicht der wichtigsten Punkte sowie ein Inhaltsverzeichnis hinzugefügt.
- Die Quellen von OpenAI, Cloudflare und Google Search Central wurden inline als Quellenangaben eingebunden.
- Die Formulierung wurde in einen sachlichen Beraterton umformuliert, und der Schlussabschnitt erhielt einen meinungsbetonten Ausklang.
Möchtest du, dass unsere Beiträge öfter bei Google erscheinen?
Ein Schritt – und Google zeigt diese Seite in Ihren „Top Stories“ an.


